Sorry if it's hard to catch my vibe -Building the Dumbest (Yet Smartest?) C2 in Existence
How well can GenAI deal with new trends?
Red Team Operator
SANS Author of SEC565: Red Team operations and Adverary Emulation. SANS Co-Author of SEC699: Advanced Purple Team Tactics.
We’re back like we never left.
Hello, dear readers! It's been a while.
Unfortunately, the old redteamer.tips had an unexpected demise due to a provider mishap—and, regrettably, backups weren't available. RIP old blog. But fear not; we’re back and ready to dive into exciting new territory!
This blog post started with a simple research question:
How well can the “well known” AI models that we love (GPT, Claude, Gemini etc…) deal with “new” research?
It was intruiging to me as of course more recent data means that the models haven’t ingested it as part of their training data. Meaning they(=the models) would have to reason and figure out how to in (and de)gest the data presented.
As it turns out, I had an interesting idea:
In my role as Director of Offensive Operations at Cytadel, I oversee offensive security consulting and help guide the development of our Ethical Ransomware product, Cytadel R3 (Redefining Ransomware Resilience). Among other features, R3 enables execution of ransomware-related TTPs. Although R3 isn’t written in C#, I realized an AI-driven experiment could provide a minimalist proof-of-concept (PoC), potentially transferable into our CLASSIFIED INFORMATION—Nice Try!.
Introducing: The Dumbest C2 in Existence! (Or is it the smartest?)
In an era where Command and Control (C2) frameworks have become increasingly sophisticated, simplicity can be revolutionary.
Imagine a minimalist C2 agent devoid of built-in functionalities but dynamically extensible via LLM-assisted capability generation. Thus, the "dumbest C2 in existence" project was born
Before I go further, I first need to talk a bit more about “LLM-assisted capability generation” So allow me to introduce…

ChatGPMCP
The new “hype” nowadays is MCP, also known as Model Context Protocol. To quote Anthropic directly
MCP is an open protocol that standardizes how applications provide context to LLMs. Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools.
Essentially, traditional AI models were limited primarily to chat-based interactions. However, recent advances (Cursor, GitHub Copilot, WindSurf, and more) empower LLMs with new abilities, known as "tools," enhancing interactions beyond mere text.
Driven by curiosity, I challenged ChatGPT-4o (henceforth "Chat") to handle fresh context:

Not off to the best of starts…
(although I liked the fact that because I put this chat in a project folder called “dumbest c2 in existence”, ChatGPT (which I from now on will just call “Chat”) assumed its a C2 in C#)
I tried giving it some context, to see if that would do anything in this model, and it actually did!

What caught my eye was the fact that they had an SDK in C#.

Time to make a plan
I wanted to see if Chat can deal with multiple things in one prompt. I also fed Chat an Image to see if it would recognize it somehow.
I want to create a very basic POC for a C# C2 but here is the thing.
The C2 does nothing. it has no built in commands, the only thing it does is establish HTTP(S) comms to the server side.what makes this interesting is that I want this C2 to be capeable of dynamically loading and unloading new capabilities. a bit like the mythic c2 framework does. https://docs.mythic-c2.net/~gitbook/image?url=https%3A%2F%2Fcontent.gitbook.com%2Fcontent%2FKbzfKI4qhfyU4PSI7wrx%2Fblobs%2FS9JtQKt3pZx5yFDA1Ihf%2FScreen%2520Shot%25202021-12-02%2520at%25203.19.58%2520PM.png&width=400&dpr=3&quality=100&sign=7589338f&sv=2
I want to do it though through an MCP so for example the c2 calls back in and I give it new C# code that it can register, and it would now have a new command!
so an example would this would be as follows:
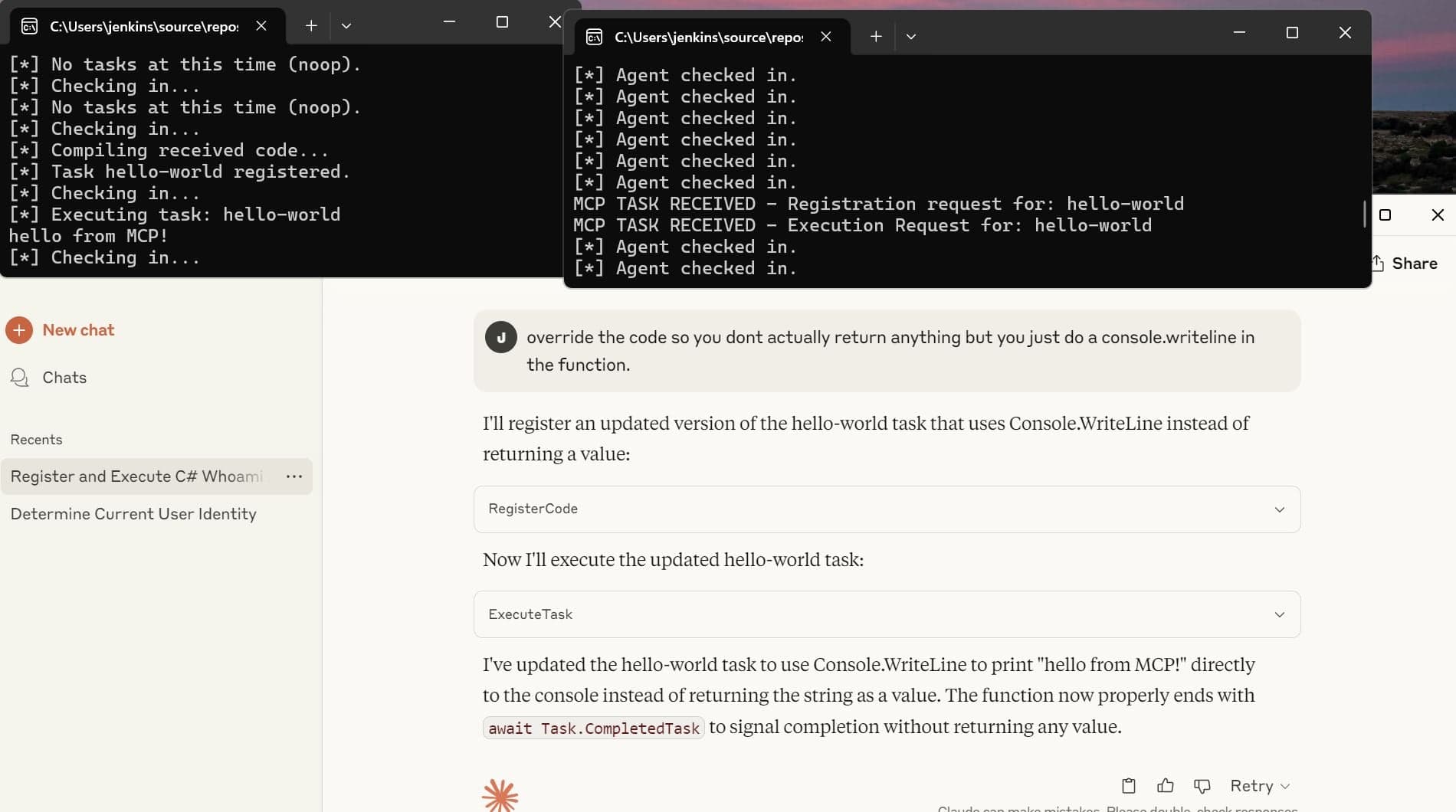
1. agent checks back in
2. operator asks LLM enumerate local groups LLM generates new C# code that does group enum for windows agent
3. receives code agent registers new task localgroupenum
4. Agent can now execute the localgroupenum task.Get it?
Surprisingly, ChatGPT-4o produced an excellent response and proactively outlined a robust implementation plan without explicit prompting. The AI’s autonomous capability to structure data effectively minimized user-induced errors from poor prompting.



The quality of the code generated by 4o (which is not considered the “golden goose” of code generation, especially not with the newer 4.1 models and even o3, which both are still slightly below Sonnet in coding benchmarks.) was unexpectedly solid, employing MVC patterns, Dependency Injection, and class separation—remarkably sophisticated for an unprompted minimalist PoC.
Chat then PROACTIVELY asked me if it should generate a small console app to make end to end testing easier.

There were a few tiny bugs in the generated code, but nothing extremely significant, and Chat solved most of them in 1 prompt.
Sidenote, recently (the last 3 months) I’ve been primarely using Cursor but now that WindSurf announced they got rid of flowcredits and temporary allowed users to use the latest GPT models for free, I made the switch. However, these AI integrated assistants ALL seem to have the same problem, which is that when you want to modify something, the AI modifies WAY TOO MUCH. Some users reported losing quite a bit of work (of course not that big of a deal if you are using proper subversioning, but still). Taking the GPT chat approach instead of the agentic approach actually seems to work rather nicely, even though the “official” GPT web application does not support ALL of the models they expose in Windsurf/Cursor
However, I did notice that once we hit a semi persistent bug (the server tasked something to the agent, but the agent did not receive the tasking correctly), Chat did seem to have issues pinpointing it, requiring me to step in and guide it (slightly more than what I think should be needed) towards the root cause. I wonder if it has to do with Context limits, but can’t confirm at this time.
But everything changed when the fire nation attacked
the LLM started halucinating
As much as I was impressed with the code that was generated so far, things took a horrible turn for the worse when it was time to actually implement the MCP server. I could already see it was going to go sideways from the first header Chat generated.

While this is not true, the code it produced actually made sense, and amusingly enough, I actually liked some of the implementation details that came back. For example, the concept of exposing a “Manifest”:

I tried steering it back into the right direction by pointing it towards the official reference documentation once again, but that made matters worse…

That’s when I decided to change the model to O3 instead of 4o, as O3 is a “reasoning” model, I figured it might be better equiped to actually “think” about the reference spec and come up with a solution.

This worked reasonably well, except even O3 made one crucial mistake. It was trying to combine my C2 server and MCP server into one, which I honestly thought was a pretty solid idea.
The problem with that approach, though, is that MCP servers do not want anything piped into STDOUT. This means your console output should be completely empty, which is not ideal if your server is a console application and doesn't send data to a nice frontend.
Once switched to O3, the code generation worked pretty well again and actually implemented a decent MCP server.
What was really mind-blowing to me, though, is that I had issues with getting Claude to interpret my MCP server (even though I split it out, dotnet run --nobuild still borked Claude). I fed the information to ChatO3, and it came up with a fix that wasn’t even documented in the official reference spec for MCP servers. (The fix was to compile it to an exe and point Claude to the exe instead of dotnet run.)

To Conclude
When it comes to using LLMs for quickly prototyping, I am pleasantly surprised by the results. You need minimal coding knowledge to create a coherent proof of concept. Knowing when to switch models for specific tasks can definitely boost productivity.
I prefer the separate GPT - Code Editor approach because it gives the prompter full control over the project. While an agent-based approach might be the future, my experiences with Cursor and Windsurf show that it's a delicate balance between increased productivity and agents being too eager to tweak code, delete functionality, or modify too many files. Some of these issues can be addressed with "rules," but for now, I believe the separate approach is best. Note that you can also "chat" with LLMs in integrated IDEs like Cursor, but it uses the same credits as agent actions, which isn't ideal for cost-effectiveness.
At the end of our experiment, we have a basic proof of concept working. Of course, this is not ready for production. We lack session management, task IDs, and agent IDs, and we rely on console.print in the agent instead of sending the output back to the server, so there's definitely still a long way to go. However, considering it took about 4 hours to create, I find this quite impressive.
You can find the source code for the project here:
https://github.com/Cytadel-Cyber/BlogPosts/tree/main/DumbestC2Ever